
こんにちは、YamaCです。自分の覚えのためにいろいろ書きます。
LocalLLMを試してみた記録です。
前提とやること
前提:
・WSLにUbuntu Server 24.04 / Dockerは導入済み。/GPU関係のいろいろも導入済み
・筆者の環境:i5-13400、RAM32GB、RTX2060(6GB)
ゴール:
1.Docker Hubの公式コマンドでOllamaを立ち上げる
2.モデル(軽いやつ)を入れる
3.CLIで対話できることを確認する
4.Open WebUIでブラウザからLLMを触れるようにする
DockerでOllamaを立ち上げる
※DockerでNvidia Driverを使う設定はすでに済んでいるものとします。詳しくはOllamaのDocker Hubに書いてあるので、そこのコマンドを貼り付けながらエラーが出たらChatGPTに聞けばいいと思う。
https://hub.docker.com/r/ollama/ollama
やること:コンテナをrunする
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaだいたいイメージサイズが1.5GBくらいなので、まあまあ時間かかります。ゆっくり待ちましょう。
ポート11434で公開されます。
curl -s http://127.0.0.1:11434でCLIに”Ollama is running”と帰ってきたら大丈夫なはず。
モデルを入れる(Qwen3 0.6B)
まずはさっきrunしたdockerコンテナに入りましょう
docker exec -it ollama bash入ったら、モデルをインストールしましょう。今回は最近話題のqwen3の軽いモデル、”qwen3 0.6B”を使います。
ちなみに、ollamaのsearchのページをみると、いろいろなモデルが見れるので、qwrn3:0.6Bでなくても動かしたいものがあればそれで大丈夫です。
ollama pull qwen3:0.6b完了したら ollama list で確認できます。
NAME ID SIZE MODIFIED
qwen3:0.6b 7df6b6e09427 522 MB 2 days agoこんな感じで確認できるはずです。
CLIで動くことを確認してみる
というわけで、入れたモデルを早速動かしてみましょう
ollama run qwen3:0.6bしばらくくるくるした後に”Send a message”と言われるので試しに「日本語でqwen3について自己紹介して」なんて聞いてみると
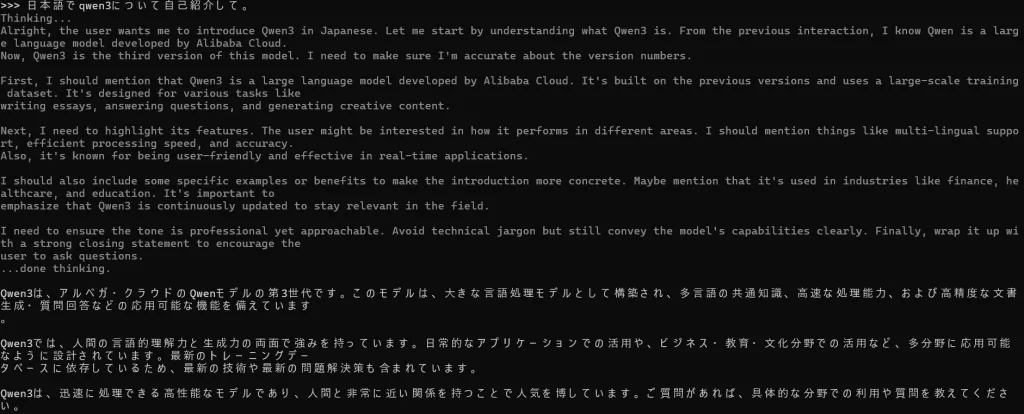
こんな感じで返ってきます。動作が問題ないことをこれで確認できます。あとは対話履歴をクリアしたり、モデルの情報を表示したりは /?で確認できるのでやってみてください。
終了はCtrl + dです。
WebUI(Open WebUI)で触ってみる
一番カンタンな起動方法はこちら(Ollamaはホストの11434で稼働中という前提)(GPUを使っている前提)
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cudaあとは、localhost:3000に飛べばOPEN WEBUIにアクセスできます。会員登録みたいなものだけしたらモデルが選択できるはず。
詳しくはここに書いてます。 https://github.com/open-webui/open-webui
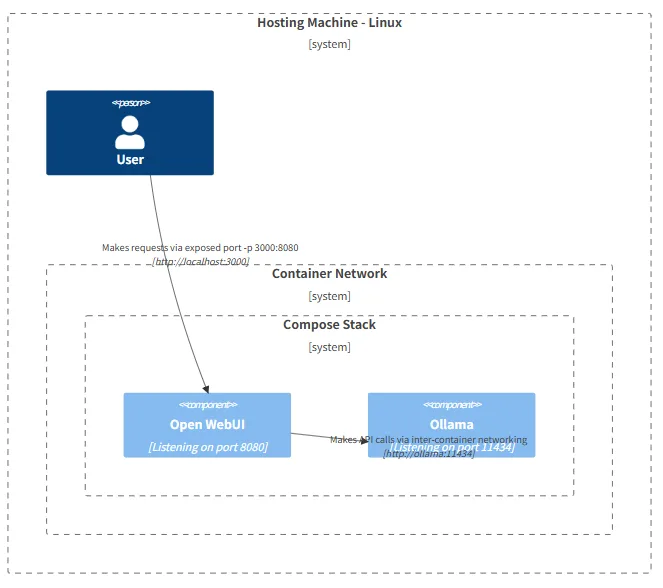
ここの図もめちゃくちゃわかりやすいので、おすすめ。今回は別々のコンテナで実行したけど、この図で示されているような、1コンテナで構成したほうがわかりやすいかも。
https://docs.openwebui.com/getting-started/advanced-topics/network-diagrams/#mac-oswindows-setup-options-%EF%B8%8F
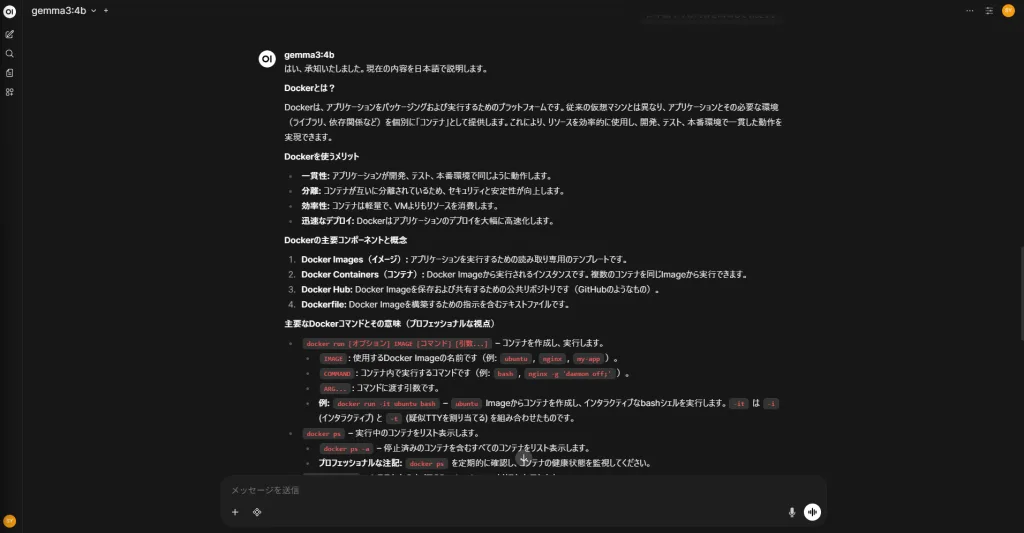
こんな感じで、よく見る感じのUIで触れるのでおすすめ。(てか、Gemma3ってすごいべ。4Bモデルでもちゃんとしてる。舐めてました。)
まとめ
というわけで、Dockerをフル活用して、OllamaとWebUIでLocalLLMお試しを簡単にやってみました。
感覚的には4Bモデルは筆者の環境だと比較的普通に動きます。8Bモデルはちょっと重いかな・・・回答来ないな・・・という感じ。
モデルのサイズ、あまり意識したことはなかったけど、比較的最近出たGPT-OSSは120Bでしょ。4Bでも割と頑張ってるな!と思ったのに、30倍ってすごい。80GBのグラボで動くらしい。
次はローカルRAGを構築する回でお会いしましょう
